
Sobre el Proyecto
ESTIM es un proyecto de Lenguaje de Marcas planteado como un sistema completo alrededor de un catálogo de videojuegos, no como una única interfaz visual. La idea central consiste en usar XML como base de datos documental y reutilizar ese mismo modelo en varias capas: validación, presentación directa, transformación XSLT y aplicación web interactiva.
Lo que hace interesante el proyecto no es solo la cantidad de tecnologías que reúne, sino la forma en que se relacionan entre sí. El XML actúa como fuente de verdad y, a partir de él, se obtienen distintas salidas con objetivos diferentes: control de integridad, visualización estructurada, transformación a HTML y una SPA que añade búsqueda, filtros, traducción, moneda y carrito sin duplicar los datos.
Arquitectura del Proyecto
La estructura del proyecto está organizada por capas bien diferenciadas: XML como núcleo de datos, DTD y XSD para validación, CSS para estilización directa del documento, XSLT para generar una salida HTML y una aplicación web construida con HTML, CSS y JavaScript para consumo interactivo del catálogo. A eso se suma una pequeña capa de automatización por consola, pensada para validar, consultar y transformar el documento sin depender del navegador.
XML como fuente de verdad
El catálogo centraliza el dato y evita repartir la información entre varias representaciones incompatibles.
DTD y XSD para validación
La integridad del documento se controla en dos niveles: uno estructural y otro más estricto, con tipos y restricciones.
CSS sobre XML
El propio documento puede presentarse en el navegador sin transformarlo antes a HTML convencional.
XSLT como salida documental
La misma base de datos se transforma a una representación HTML distribuible y orientada a lectura.
SPA para consumo interactivo
JavaScript parsea el XML, lo convierte en objetos y construye filtros, vistas y carrito sin hardcodear el catálogo.
Shell como capa operativa
La automatización por consola completa el proyecto con validación, consultas y transformación fuera del navegador.
Esa separación evita que la lógica de negocio quede mezclada con la representación visual. En términos de portafolio, el valor del proyecto está precisamente en mostrar que un mismo conjunto de datos puede sostener distintos canales de salida con responsabilidades claras y tecnologías adecuadas para cada caso.
XML como Núcleo del Sistema
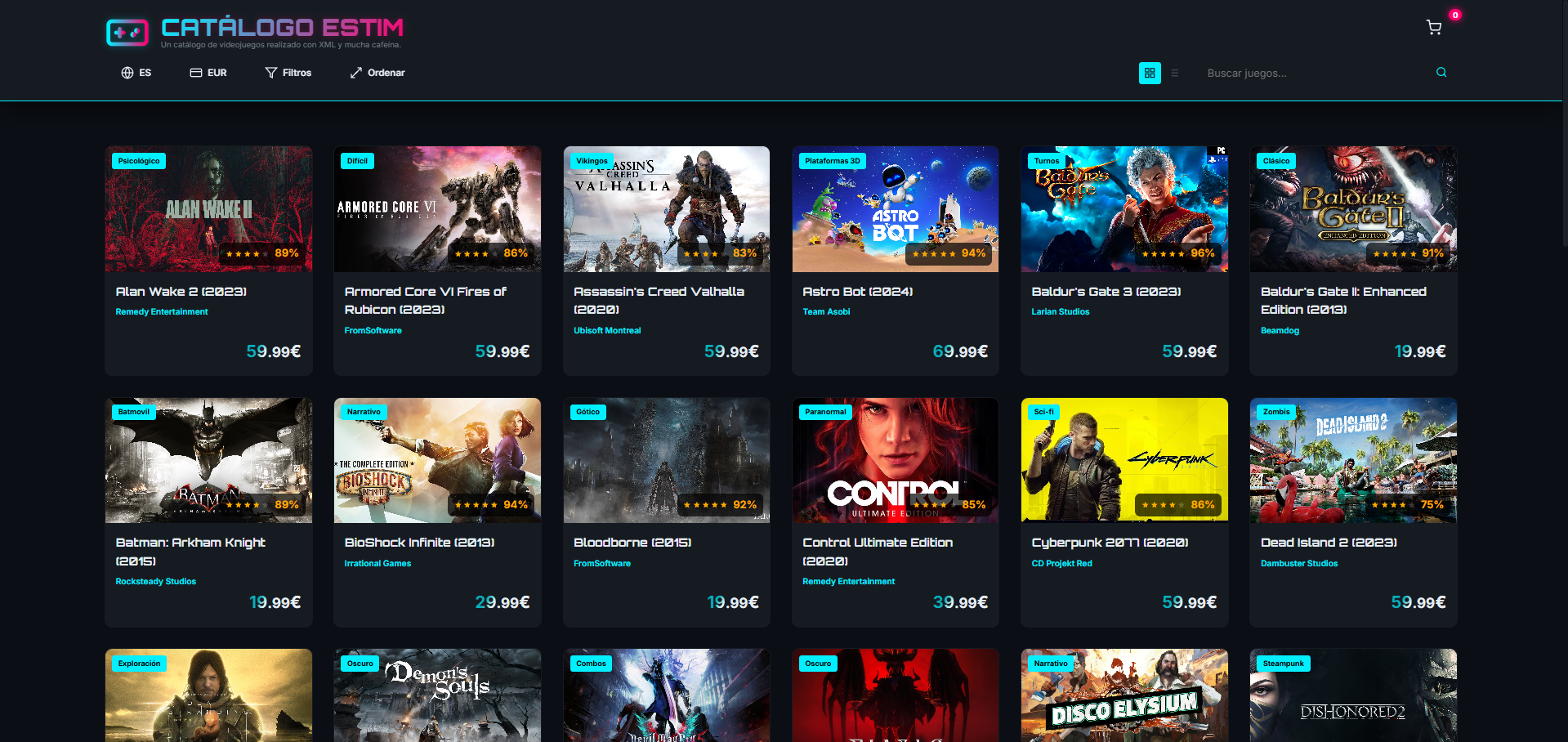
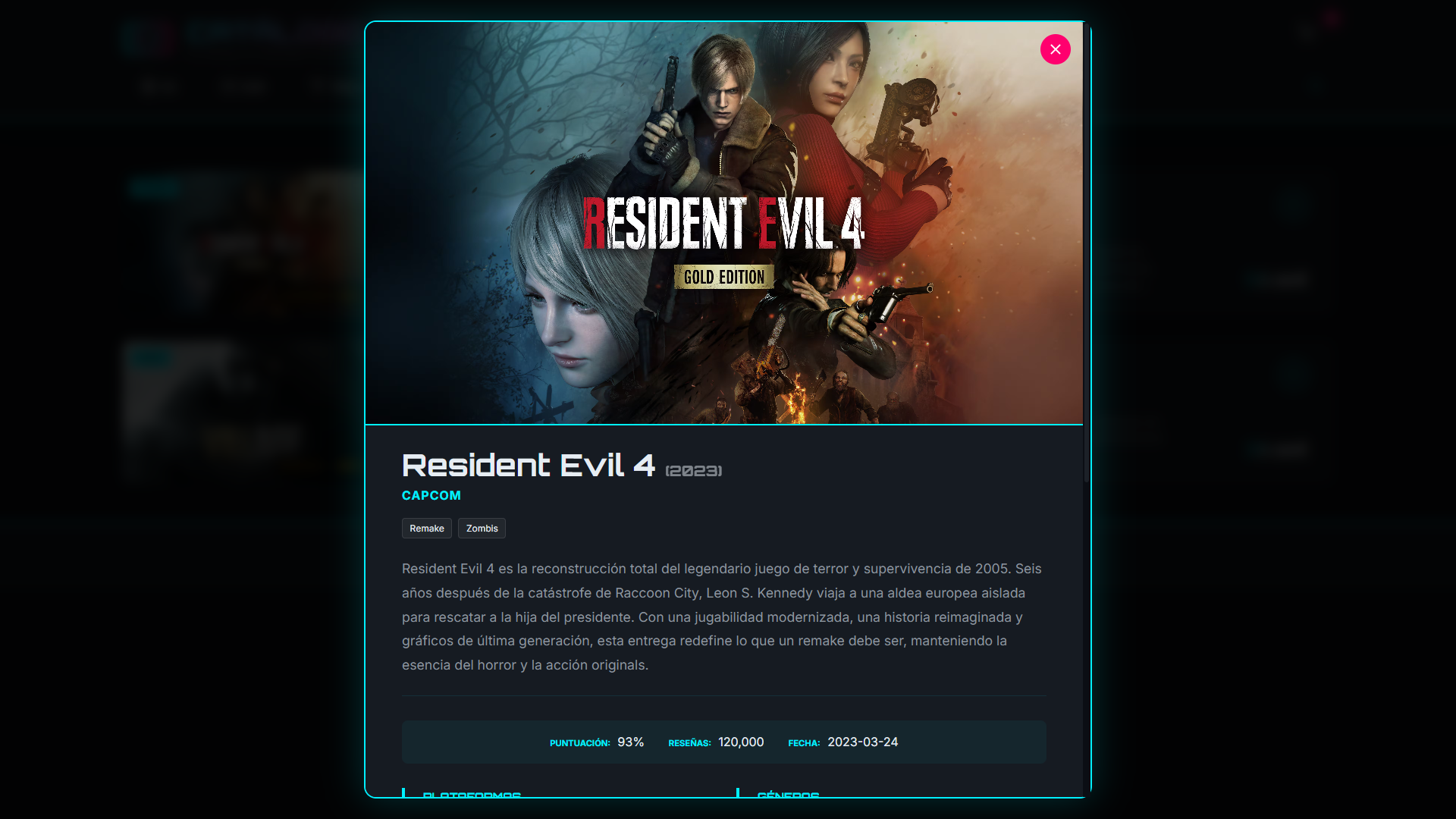
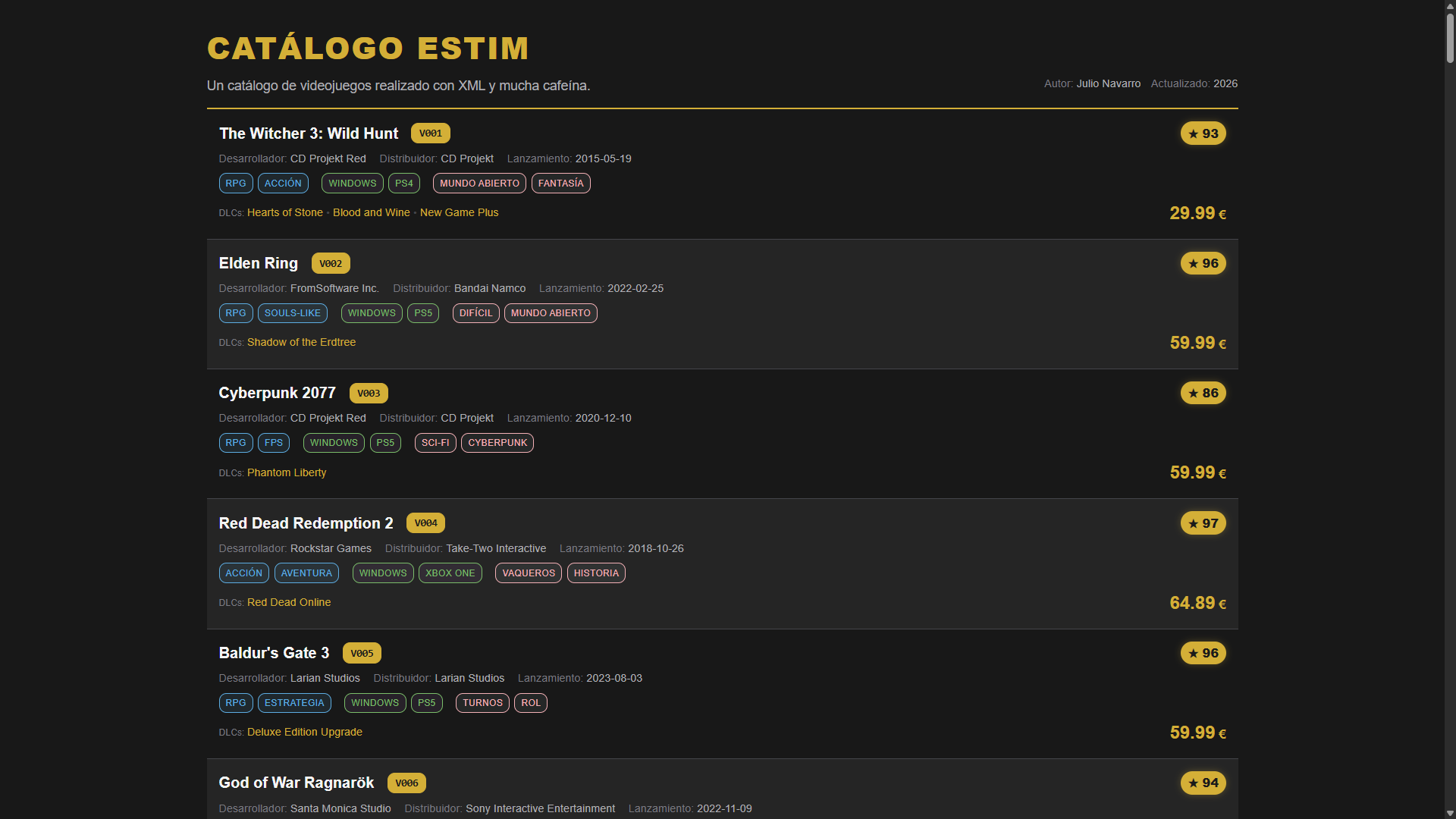
El catálogo almacena bastante más que un listado básico de títulos. Cada videojuego incorpora título, descripciones en varios idiomas, desarrollador, distribuidor, fecha de lanzamiento, géneros, plataformas, precios por moneda, puntuación, número de reseñas, requisitos mínimos y recomendados, etiquetas y DLCs, lo que convierte el XML en un modelo rico y reutilizable.
También hay un bloque de metadatos del catálogo con título y descripción en varios idiomas, autor y fecha, lo que refuerza la idea de que la internacionalización no se resuelve solo en la interfaz, sino en el propio documento de datos. Esa decisión es importante porque permite que distintas capas consuman el mismo contenido multilingüe sin rehacerlo en cada tecnología.
El esquema del catálogo deja claro que existe una capa de metadatos separada del listado de juegos y que los textos principales admiten varios idiomas mediante xml:lang.
<xs:element name="catalogo">
<xs:complexType>
<xs:sequence>
<xs:element name="info">
<xs:complexType>
<xs:sequence>
<xs:element name="titulo" minOccurs="1" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute ref="xml:lang" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>Esa estructura no solo ordena el documento, sino que prepara el catálogo para reutilizarse en varios idiomas desde el origen del dato.
Validación y Namespaces
La validación está planteada en dos niveles: una validación estructural con DTD y una validación más estricta con XSD. Ese segundo nivel introduce tipado fuerte, restricciones numéricas, enumeraciones y patrones, algo especialmente útil en un catálogo con identificadores, fechas, monedas, plataformas, puntuaciones y requisitos técnicos.
Qué aporta cada capa de validación
Además, la validación XSD está separada en dos esquemas: uno para el catálogo general y otro para la entidad videojuego. Esa modularidad mejora la legibilidad, reparte responsabilidades y hace que el proyecto sea más mantenible que un único esquema monolítico.
Un detalle especialmente acertado es el uso de namespaces para diferenciar los metadatos del catálogo y los datos de los juegos. En un proyecto académico esto aporta orden semántico, pero también tiene una consecuencia práctica: evita colisiones de nombres y deja preparado el documento para crecer sin perder claridad.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://estim.com/cataleg"
xmlns:catalogo="http://estim.com/cataleg"
xmlns:juego="http://estim.com/videojuego"
elementFormDefault="qualified">
<xs:import namespace="http://estim.com/videojuego" schemaLocation="videojuego.xsd" />
</xs:schema>En el esquema de videojuego se ve aún mejor esa intención de validación fuerte, por ejemplo con tipos reutilizables para puntuación, precio, plataformas, disco o identificadores. No se trata solo de comprobar si una etiqueta existe, sino de garantizar que su valor tiene sentido dentro del dominio del catálogo.
Estilización Directa del XML
Uno de los aspectos menos habituales del proyecto es la visualización directa del XML con CSS. En lugar de transformar primero el documento a HTML, se aprovecha que el navegador puede aplicar estilos a etiquetas XML si se definen correctamente los namespaces y el comportamiento visual de cada nodo.
La hoja cataleg.css convierte una estructura documental en una interfaz legible con jerarquía visual, color, bloques, etiquetas y comportamiento responsive. Eso tiene interés técnico porque demuestra una capa de presentación poco común, pero muy alineada con los objetivos de trabajar sobre el propio marcado, no solo sobre HTML convencional.
@namespace catalogo "http://estim.com/cataleg";
@namespace juego "http://estim.com/videojuego";
@namespace xml "http://www.w3.org/XML/1998/namespace";
catalogo|titulo:not([xml|lang="es"]),
catalogo|descripcion:not([xml|lang="es"]),
juego|descripcion:not([xml|lang="es"]),
juego|precio:not([moneda="EUR"]) {
display: none;
}Ese fragmento resume bien dos decisiones importantes: usar selectores con namespaces y filtrar visualmente idioma y moneda desde CSS. No es una solución para una aplicación dinámica, pero sí una demostración muy clara de cómo el mismo XML puede tener una presentación útil incluso sin pasar por JavaScript ni por una transformación previa.
Técnica de line breakers
La solución más creativa de esta capa es la técnica de los line breakers. Como el XML tiene una estructura plana de elementos hermanos, el CSS introduce nodos ocultos que fuerzan saltos de línea dentro del flujo flex para reconstruir visualmente cada videojuego como si fuera una tarjeta con filas internas.
&>juego|descripcion {
order: 4;
display: block;
width: 100%;
height: 0;
margin: 0;
visibility: hidden;
}
&>juego|requisitos {
order: 8;
display: block;
width: 100%;
height: 0;
margin: 0;
visibility: hidden;
}Es una solución poco ortodoxa, pero precisamente por eso resulta interesante para el portafolio. Resuelve una limitación de maquetación sin alterar el orden documental del XML y deja claro que hubo intención de diseño, no solo aplicación de estilos básicos.
Transformación XSLT
La capa XSLT introduce una segunda estrategia de salida a partir del mismo catálogo. Frente a la visualización directa del XML, aquí la idea ya no es vestir el documento original, sino transformarlo en una representación HTML más convencional y distribuible.
El proyecto incluye tanto el motor XSLT como un HTML generado a partir de esa transformación (cataleg.html), y además contempla una salida orientada a impresión. Eso convierte el catálogo en un documento reutilizable: el mismo dato puede verse como XML estilizado, como página HTML transformada o como base de una SPA.
Pipeline de transformación
El script de automatización deja muy clara esa cadena de trabajo:
XSL_FILE="$DIR/cataleg.xsl"
HTML_OUTPUT="$DIR/cataleg.html"
if xsltproc -o "$HTML_OUTPUT" "$XSL_FILE" "$XML_FILE" 2>&1; then
echo -e "${VERDE}✓ Transformación completada${NC}"
echo -e "${VERDE} Archivo generado: $HTML_OUTPUT${NC}"
fiEn la práctica, esta capa aporta algo más que otra manera de verlo. Demuestra reutilización documental y separación entre contenido y presentación, dos ideas muy relevantes cuando se trabaja con tecnologías de marcas de forma seria.
Aplicación Web Interactiva
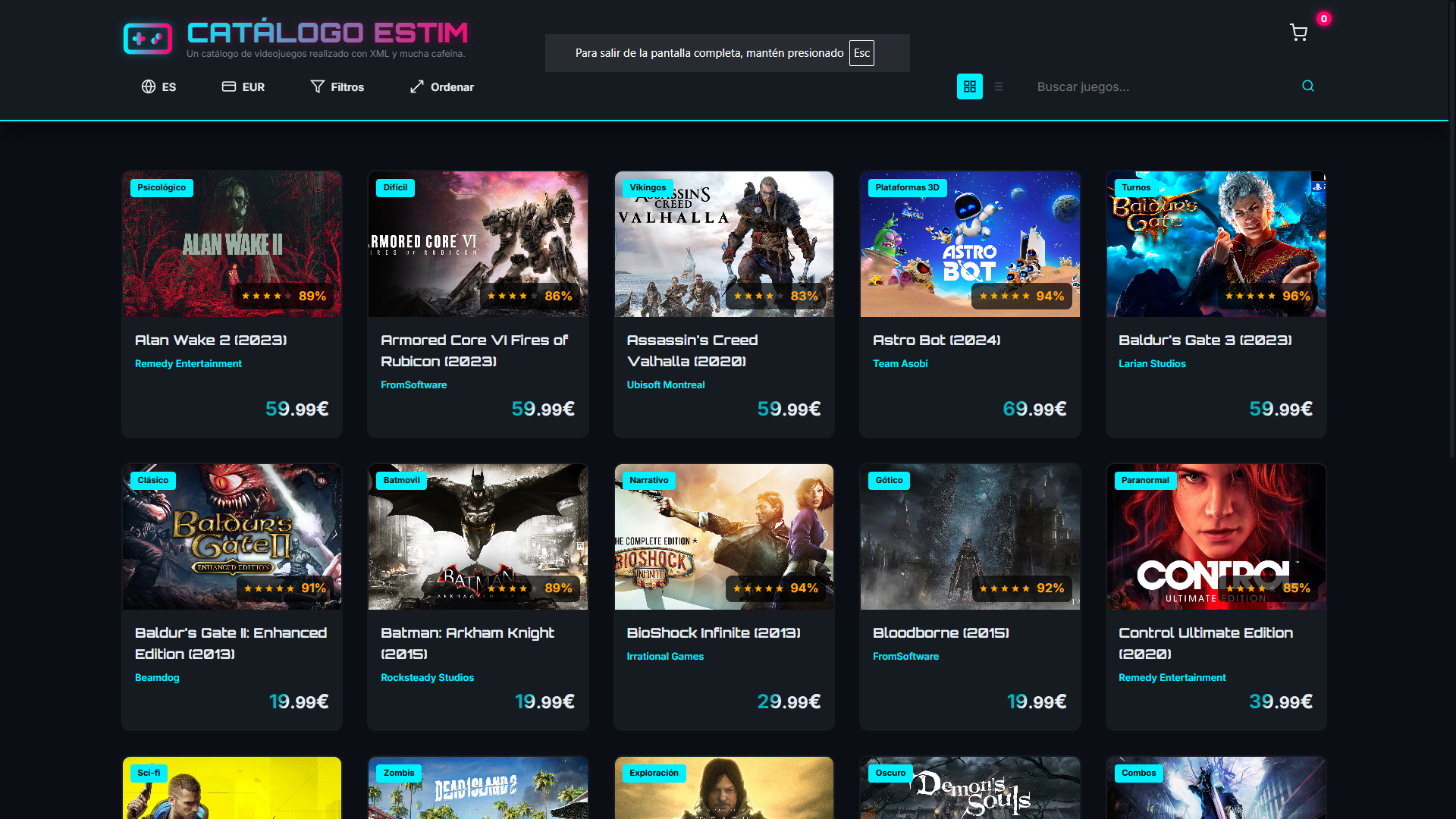
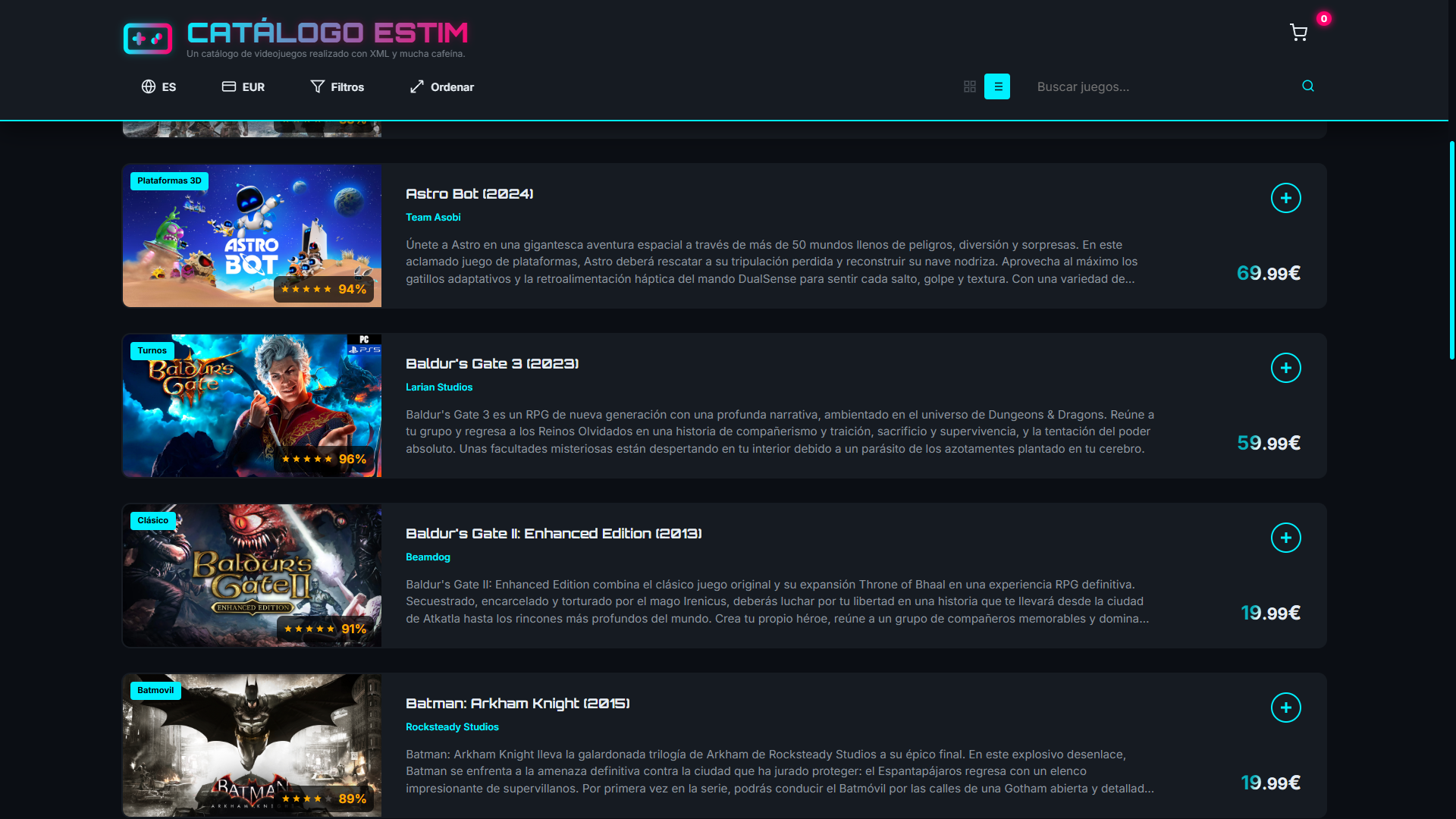
La SPA es la capa donde el proyecto se acerca más a una aplicación real. El script app.js carga el XML, lo parsea en el navegador y construye dinámicamente las tarjetas, los filtros, los selectores y la vista general del catálogo sin depender de un listado HTML estático.
La lógica está organizada alrededor de un pequeño estado global y de funciones con responsabilidades bastante claras: carga de datos, parseo de requisitos, procesado del catálogo, actualización de la vista y renderizado. Esa organización ayuda a que la aplicación no sea solo una suma de eventos sueltos, sino una capa coherente sobre el modelo XML.
La entrada a la aplicación consiste en leer el XML y convertirlo en una estructura manipulable desde JavaScript.
async function loadXML() {
const response = await fetch('cataleg.xml');
const text = await response.text();
const xml = new DOMParser().parseFromString(text, 'text/xml');
}Esta decisión evita duplicar el catálogo en JSON o en HTML y mantiene el XML como origen único del sistema.
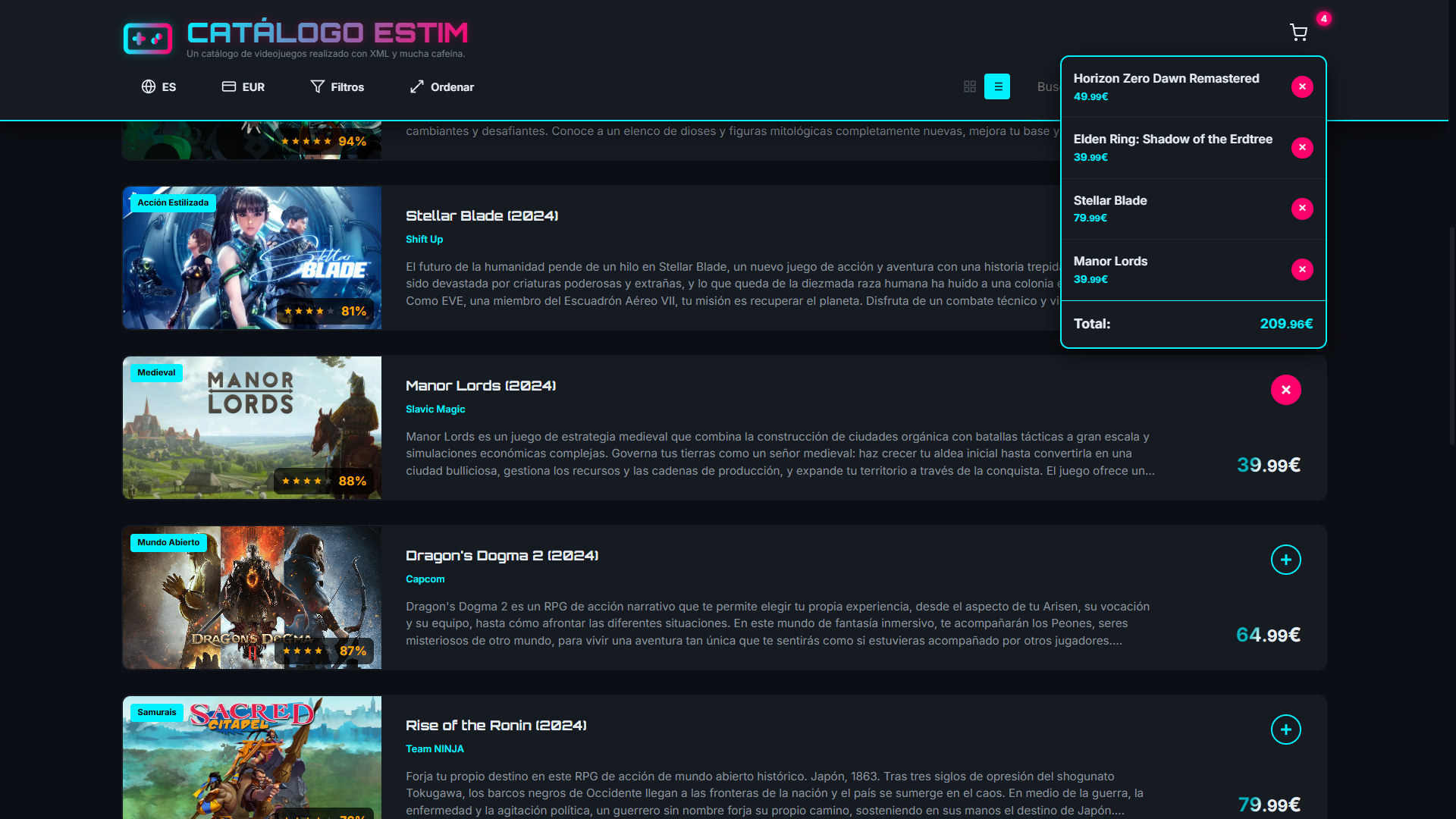
La aplicación incorpora además funciones propias de un catálogo comercial: filtrado por géneros, plataformas y etiquetas, ordenación por distintos criterios, cambio de moneda, traducción en tiempo real y un carrito de compra con persistencia. En conjunto, esta capa convierte un ejercicio de marcas en una interfaz navegable que demuestra separación entre datos, presentación y lógica de interacción.
Scripts y Automatización
El archivo xml_scarlet.sh amplía el proyecto hacia un contexto más técnico y menos dependiente del navegador. No es un simple script accesorio: agrupa validación con DTD y XSD, consultas XPath, conteos, sumas, extracción de información y ejecución de la transformación XSLT desde un menú de terminal.
Operaciones cubiertas por el script
if xmllint --valid --noout "$XML_FILE" 2>&1; then
echo -e "${VERDE}✓ El XML es válido según el DTD${NC}"
fi
if xmllint --schema "$XSD_FILE" --noout "$XML_FILE" 2>&1; then
echo -e "${VERDE}✓ El XML es válido según el XSD${NC}"
fiEse tipo de automatización es relevante porque muestra que el catálogo no está pensado solo para verse, sino también para comprobarse y explotarse como documento estructurado. El mismo script incluye consultas XPath, estadísticas del catálogo y extracción de juegos concretos, lo que añade una dimensión práctica muy útil a nivel académico.
Alcance Técnico
ESTIM demuestra varias cosas a la vez dentro de un mismo proyecto. Demuestra modelado de datos con XML, validación con varios niveles de exigencia, uso correcto de namespaces, técnicas de presentación no habituales como el CSS directo sobre XML, transformación documental con XSLT y consumo del catálogo desde una capa web interactiva.
Pero, sobre todo, demuestra una idea que vale mucho en un portafolio técnico: el proyecto no depende de una única interfaz ni de un único formato de salida, y precisamente por eso funciona bien como pieza de muestra para demostrar estructura, control, reutilización y criterio de diseño técnico en un mismo desarrollo.